
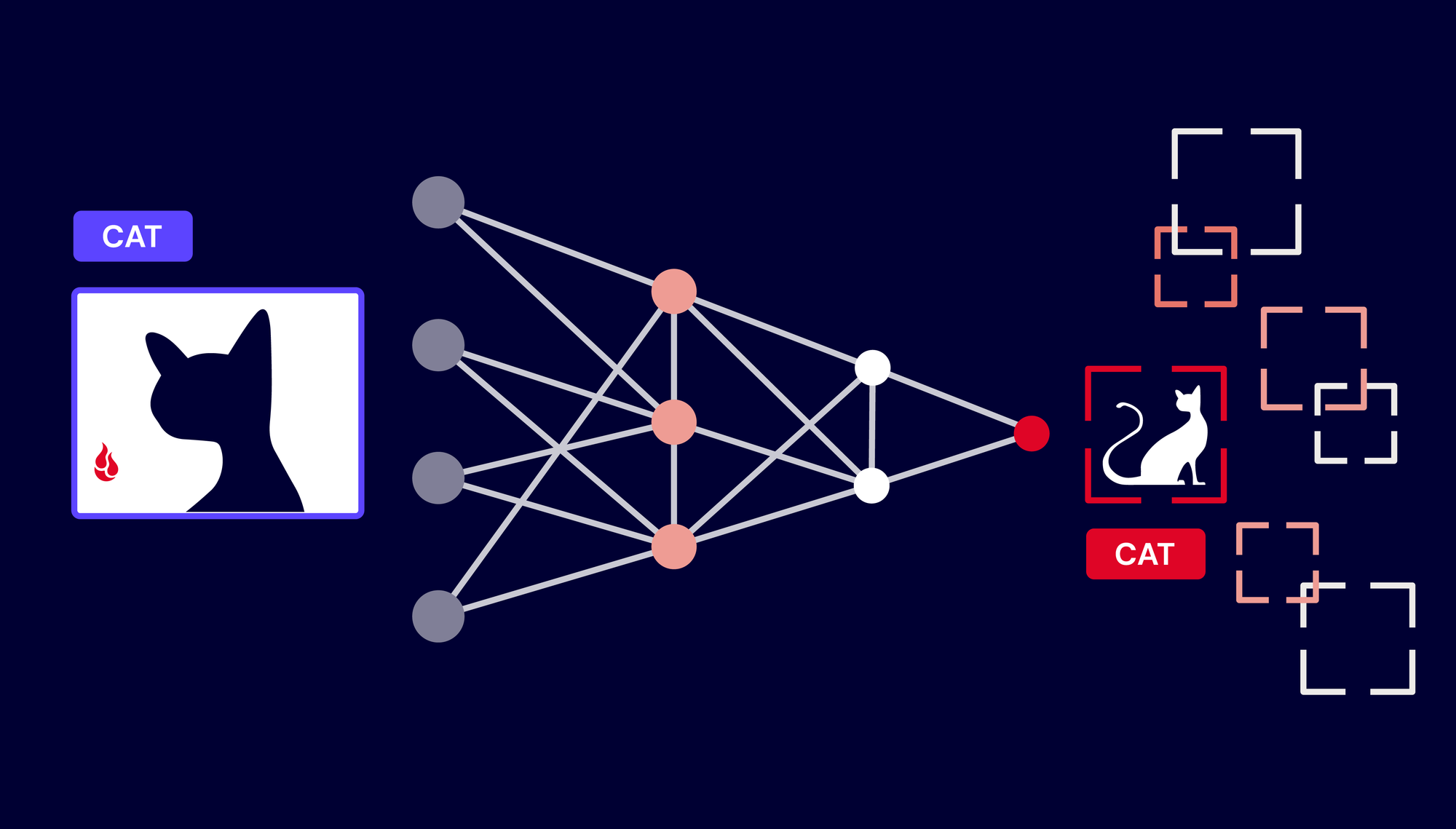
The advent of Large Language Models (LLMs) such as GPT, Gemini, and others has fundamentally transformed our approach to product and system development. However, the most significant hurdle we currently face as builders/developers is their inherent cost and pricing models.
The immense price tag is the major bottleneck, and most AI products are surviving on VCs subsidies. This in turn is creating significant barriers to widespread, real-time model integration in most apps. A typical AI productivity tool subscription can range from $20 per month to $1000 and above. The cost of inference on these LLMs foundation models is just too high.
Most of these apps charging hundreds of dollars monthly are still nowhere near being sustainable, given that most can pull this off because they can still raise hundreds of millions of dollars from VCs. We can all deduce that this model as it is now, can't be sustainable.
A Blast from the Past: TensorFlow Lite and On-Device AI
While the idea of "local AI" might seem like a recent trend driven by the rise of large language models (LLMs), it's important to remember that the concept of on-device inference is not new. In fact, just a few years ago, we were actively developing and implementing local inference on Android devices using frameworks like TensorFlow Lite
I remember 7-10 years ago we used to be all excited about the idea of specialized small model blobs that we could embed in mobile devices and being able to actually directly run inference locally, no internet needed, no need for insane tokens pricing models.
I had build a pretty performant proof of concept Android app that had an embedded model capable of doing on device image recognition pretty fast.
Why we need to develop edge/local friendly models.
The trend towards directly embedding small AI models into applications for local inference is in my opinion a necessity and a game-changer, especially for mobile devices. It addresses many of the limitations of relying solely on large, cloud-based models.
Here's a breakdown of the key advantages:
(i) Cost Efficiency
- Eliminate Cloud Fees: Running inference on a cloud server incurs recurring costs based on usage (e.g., per token for LLMs, per inference for image processing). By performing inference locally, we can significantly reduce or even eliminate these operational expenses, leading to substantial cost savings, especially for apps with a large user base or high usage.
- Predictable Costs: The costs are upfront (model development and app integration), rather than variable monthly bills from cloud providers.
(ii) Enhanced Privacy and Security
- Data Stays On-Device: This is arguably the most significant advantage. When AI inference happens locally, sensitive user data (photos, voice recordings, personal text, health data) never leaves the device. This eliminates the need to transmit data to external servers, drastically reducing the risk of data breaches, unauthorized access, and privacy violations.
- Compliance: For industries with strict data privacy regulations (like healthcare under HIPAA or general data protection under GDPR), local inference simplifies compliance, as sensitive information doesn't need to be managed by third-party cloud providers.
- User Trust: Users are increasingly concerned about their data. Apps that clearly state and demonstrate on-device processing build greater user trust and confidence.
(iii) Reduced Latency and Real-time Responsiveness
- Instantaneous Feedback: By eliminating the network round-trip to a cloud server, local inference provides near-zero latency. This means AI-powered features can respond in milliseconds, leading to a much smoother and more natural user experience.
- Real-time Applications: This is critical for applications that require immediate responses, such as:
- Live camera filters/effects: Applying AI effects to video streams in real-time.
- On-device speech recognition and translation: Instantaneous voice commands and language translation.
- Augmented Reality (AR): Real-time object recognition and scene understanding for AR experiences.
- Predictive text and smart replies: Generating suggestions as you type.
(iv) Offline Functionality
- No Internet Required: Small embedded models can function perfectly well without an active internet connection. This makes the AI features available in remote areas, during travel (e.g., on a plane), or in situations with unreliable network connectivity.
- Increased Reliability: The app's AI features are not dependent on external network infrastructure, making them more robust and less prone to disruptions from server outages or internet problems.

(v) Energy Efficiency and Resource Optimization
- Optimized for Device Hardware: Small models are specifically designed and optimized to run efficiently on the limited computational resources (CPU, GPU, Neural Processing Units/NPUs) of mobile devices.
- Lower Power Consumption: Efficient models require less processing power, which translates to reduced battery drain on mobile devices, enhancing user convenience.
(vi) Personalization and Customization
- Contextual Understanding: Local models can leverage on-device data and user behavior patterns to provide highly personalized experiences without sending that personal data to the cloud.
- Tailored Experiences: An app can adapt its AI features based on individual user habits, preferences, and context, leading to more relevant recommendations, content, and interactions.
(vii) New Use Cases and Innovation
- Unlocking New Possibilities: The combination of low latency, privacy, and offline capabilities opens up entirely new categories of applications that were previously impractical or impossible with cloud-only AI.
- Edge Intelligence: This approach empowers "edge computing," bringing intelligence directly to where the data is generated, fostering innovation in areas like smart home devices, wearables, and industrial IoT.
Conclusion
While a big chunk of R&D is focusing on very powerful multipurpose LLMs, I believe there's a real need for local small embeddable models.
These will be used on specialized applications demanding real-time responses, offline capability, stringent privacy, and cost-efficiency.
The emphasis will increasingly be on highly optimized small models deployed directly on edge and mobile devices.